Deploy a Cluster with Terraform
The Spectro Cloud Terraform provider enables you to create and manage Palette resources in a codified manner by leveraging Infrastructure as Code (IaC). Some notable reasons why you would want to utilize IaC are:
-
The ability to automate infrastructure.
-
Improved collaboration in making infrastructure changes.
-
Self-documentation of infrastructure through code.
-
Allows tracking all infrastructure in a single source of truth.
If want to become more familiar with Terraform, we recommend you check out the Terraform learning resources from HashiCorp.
This tutorial will teach you how to deploy a host cluster with Terraform using Amazon Web Services (AWS), Microsoft Azure, or Google Cloud Platform (GCP) cloud providers. You will learn about Cluster Mode and Cluster Profiles and how these components enable you to deploy customized applications to Kubernetes with minimal effort using the Spectro Cloud Terraform provider.
Prerequisites
To complete this tutorial, you will need the following items
-
Basic knowledge of containers.
-
Docker Desktop, Podman or another container management tool.
-
Create a Cloud account from one of the following providers.
-
Register the cloud account with Palette. Use the following resource for additional guidance.
Set Up Local Environment
You can clone the tutorials repository locally or follow along by downloading a Docker image that contains the tutorial code and all dependencies.
If you choose to clone the repository instead of using the tutorial container make sure you have Terraform v1.4.0 or greater installed.
- Docker
- Podman
- Git
Ensure Docker Desktop on your local machine is available. Use the following command and ensure you receive an output displaying the version number.
docker version
Download the tutorial image to your local machine.
docker pull ghcr.io/spectrocloud/tutorials:1.1.3
Next, start the container, and open a bash session into it.
docker run --name tutorialContainer --interactive --tty ghcr.io/spectrocloud/tutorials:1.1.3 bash
Navigate to the tutorial code.
cd /terraform/iaas-cluster-deployment-tf
If you are not running a Linux operating system, create and start the Podman Machine in your local environment. Otherwise, skip this step.
podman machine init
podman machine start
Use the following command and ensure you receive an output displaying the installation information.
podman info
Download the tutorial image to your local machine.
podman pull ghcr.io/spectrocloud/tutorials:1.1.3
Next, start the container, and open a bash session into it.
podman run --name tutorialContainer --interactive --tty ghcr.io/spectrocloud/tutorials:1.1.3 bash
Navigate to the tutorial code.
cd /terraform/iaas-cluster-deployment-tf
Open a terminal window and download the tutorial code from GitHub.
git@github.com:spectrocloud/tutorials.git
Change the directory to the tutorial folder.
cd tutorials/
Check out the following git tag.
git checkout v1.1.3
Change the directory to the tutorial code.
cd terraform/iaas-cluster-deployment-tf/
Create an API Key
Before you can get started with the Terraform code, you need a Spectro Cloud API key.
To create an API key, log in to Palette and click on the user User Menu and select My API Keys.
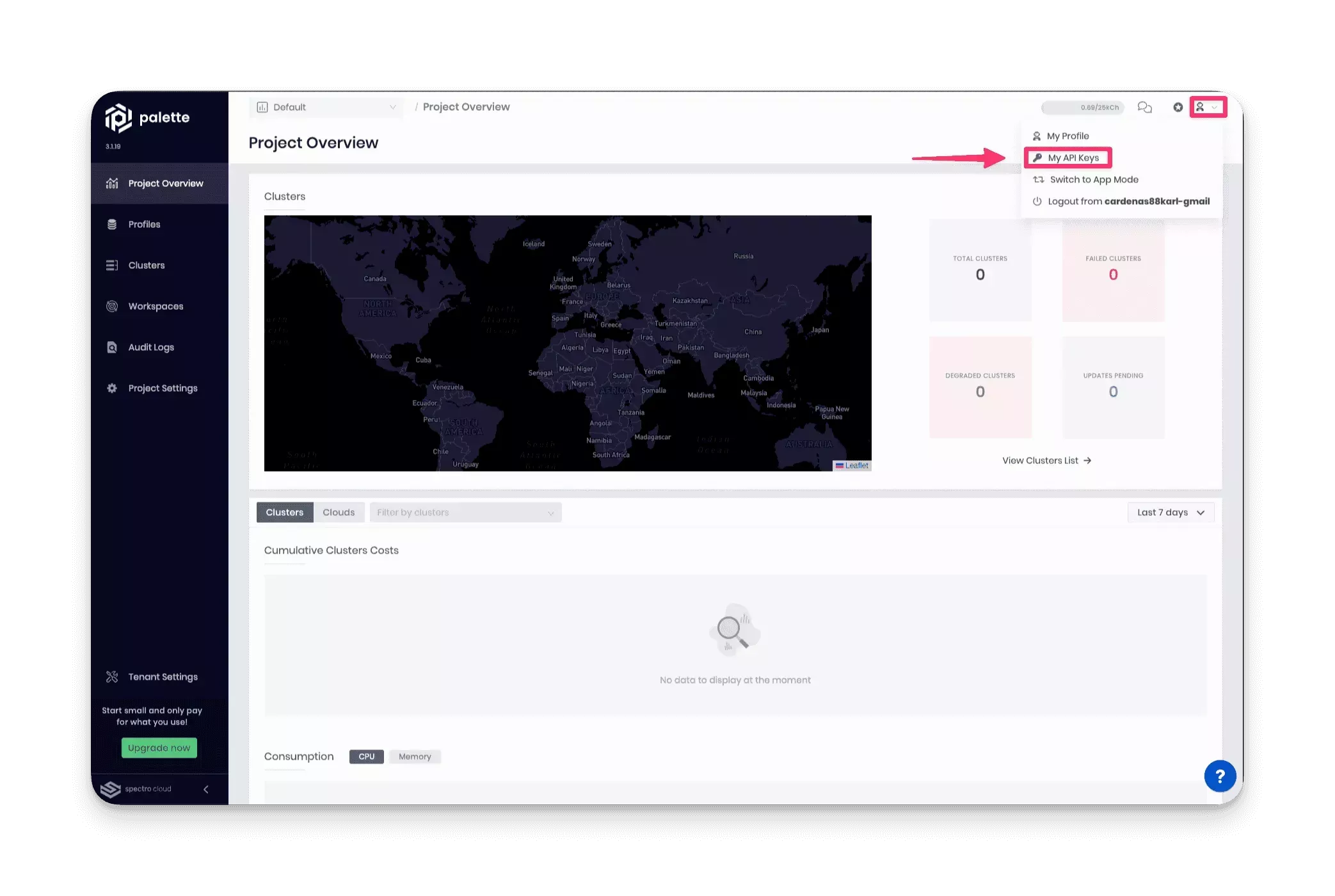
Next, click on Add New API Key. Fill out the required input field, API Key Name, and the Expiration Date. Click on Confirm to create the API key. Copy the key value to your clipboard, as you will use it shortly.
In your terminal session, issue the following command to export the API key as an environment variable.
export SPECTROCLOUD_APIKEY=YourAPIKeyHere
The Spectro Cloud Terraform provider requires credentials to interact with the Palette API. The Spectro Cloud Terraform provider will use the environment variable to authenticate with the Spectro Cloud API endpoint.
Resources Review
To help you get started with Terraform, the tutorial code is structured to support deploying a cluster to either Azure, GCP, or AWS. Before you deploy a host cluster to your target provider, take a few moments to review the following files in the folder structure.
-
providers.tf - This file contains the Terraform providers that are used to support the deployment of the cluster.
-
inputs.tf - This file contains all the Terraform variables for the deployment logic.
-
data.tf - This file contains all the query resources that perform read actions.
-
cluster_profiles.tf - This file contains the cluster profile definitions for each cloud provider.
-
cluster.tf - This file has all the required cluster configurations to deploy a host cluster to one of the cloud providers.
-
terraform.tfvars - Use this file to customize the deployment and target a specific cloud provider. This is the primary file you will modify.
-
outputs.tf - This file contains content that will be output in the terminal session upon a successful Terraform
applyaction.
The following section allows you to review the core Terraform resources more closely.
Provider
The provider.tf file contains the Terraform providers and their respective versions. The tutorial uses two
providers - the Spectro Cloud Terraform provider and the TLS Terraform provider. Note how the project name is specified
in the provider "spectrocloud" {} block. You can change the target project by changing the value specified in the
project_name parameter.
terraform {
required_providers {
spectrocloud = {
version = ">= 0.13.1"
source = "spectrocloud/spectrocloud"
}
tls = {
source = "hashicorp/tls"
version = "4.0.4"
}
}
}
provider "spectrocloud" {
project_name = "Default"
}
The next file you should become familiar with is the cluster-profiles.tf file.
The Spectro Cloud Terraform provider has several resources available for use. When creating a cluster profile, use
spectrocloud_cluster_profile. This resource can be used to customize all layers of a cluster profile. You can specify
all the different packs and versions to use and add a manifest or Helm chart.
In the cluster-profiles.tf file, the cluster profile resource is declared three times. Each instance of the resource
is for a specific cloud provider. Using the AWS cluster profile as an example, note how the cluster-profiles.tf file
uses pack {} blocks to specify each layer of the profile. The order in which you arrange contents of the pack {}
blocks plays an important role, as each layer maps to the core infrastructure in a cluster profile.
The first listed pack {} block must be the OS, followed by Kubernetes, the container network interface, and the
container storage interface. The first pack {} block in the list equates to the bottom layer of the cluster profile.
Ensure you define the bottom layer of the cluster profile - the OS layer - first in the list of pack {} blocks.
resource "spectrocloud_cluster_profile" "aws-profile" {
name = "tf-aws-profile"
description = "A basic cluster profile for AWS"
tags = concat(var.tags, ["env:aws"])
cloud = "aws"
type = "cluster"
pack {
name = data.spectrocloud_pack.aws_ubuntu.name
tag = data.spectrocloud_pack.aws_ubuntu.version
uid = data.spectrocloud_pack.aws_ubuntu.id
values = data.spectrocloud_pack.aws_ubuntu.values
}
pack {
name = data.spectrocloud_pack.aws_k8s.name
tag = data.spectrocloud_pack.aws_k8s.version
uid = data.spectrocloud_pack.aws_k8s.id
values = data.spectrocloud_pack.aws_k8s.values
}
pack {
name = data.spectrocloud_pack.aws_cni.name
tag = data.spectrocloud_pack.aws_cni.version
uid = data.spectrocloud_pack.aws_cni.id
values = data.spectrocloud_pack.aws_cni.values
}
pack {
name = data.spectrocloud_pack.aws_csi.name
tag = data.spectrocloud_pack.aws_csi.version
uid = data.spectrocloud_pack.aws_csi.id
values = data.spectrocloud_pack.aws_csi.values
}
pack {
name = "hello-universe"
type = "manifest"
tag = "1.0.0"
values = ""
manifest {
name = "hello-universe"
content = file("manifests/hello-universe.yaml")
}
}
}
The last pack {} block contains a manifest file with all the Kubernetes configurations for the
Hello Universe application. Including the application in the profile
ensures the application is installed during cluster deployment. If you wonder what all the data resources are for, head
to the next section to review them.
You may have noticed that each pack {} block contains references to a data resource.
pack {
name = data.spectrocloud_pack.aws_csi.name
tag = data.spectrocloud_pack.aws_csi.version
uid = data.spectrocloud_pack.aws_csi.id
values = data.spectrocloud_pack.aws_csi.values
}
Data resources are used to perform read actions in
Terraform. The Spectro Cloud Terraform provider exposes several data resources to help you make your Terraform code more
dynamic. The data resource used in the cluster profile is spectrocloud_pack. This resource enables you to query
Palette for information about a specific pack. You can get information about the pack using the data resource such as
unique ID, registry ID, available versions, and the pack's YAML values.
Below is the data resource used to query Palette for information about the Kubernetes pack for version 1.27.5.
data "spectrocloud_pack" "aws_k8s" {
name = "kubernetes"
version = "1.27.5"
}
Using the data resource, you avoid manually typing in the parameter values required by the cluster profile's pack {}
block.
The clusters.tf file contains the definitions for deploying a host cluster to one of the cloud providers. To create a host cluster, you must use a cluster resource for the cloud provider you are targeting.
In this tutorial, the following Terraform cluster resources are used.
| Terraform Resource | Platform |
|---|---|
spectrocloud_cluster_aws | AWS |
spectrocloud_cluster_azure | Azure |
spectrocloud_cluster_gcp | GCP |
Using the spectrocloud_cluster_azure resource in this tutorial as an example, note how the resource accepts a set of
parameters. When deploying a cluster, you can change the same parameters in the Palette user interface (UI). You can
learn more about each parameter by reviewing the resource documentation page hosted in the Terraform registry.
resource "spectrocloud_cluster_azure" "cluster" {
name = "azure-cluster"
tags = concat(var.tags, ["env:azure"])
cloud_account_id = data.spectrocloud_cloudaccount_azure.account[0].id
cloud_config {
subscription_id = var.azure_subscription_id
resource_group = var.azure_resource_group
region = var.azure-region
ssh_key = tls_private_key.tutorial_ssh_key[0].public_key_openssh
}
cluster_profile {
id = spectrocloud_cluster_profile.azure-profile[0].id
}
machine_pool {
control_plane = true
control_plane_as_worker = true
name = "control-plane-pool"
count = var.azure_control_plane_nodes.count
instance_type = var.azure_control_plane_nodes.instance_type
azs = var.azure_control_plane_nodes.azs
is_system_node_pool = var.azure_control_plane_nodes.is_system_node_pool
disk {
size_gb = var.azure_control_plane_nodes.disk_size_gb
type = "Standard_LRS"
}
}
machine_pool {
name = "worker-basic"
count = var.azure_worker_nodes.count
instance_type = var.azure_worker_nodes.instance_type
azs = var.azure_worker_nodes.azs
is_system_node_pool = var.azure_worker_nodes.is_system_node_pool
}
timeouts {
create = "30m"
delete = "15m"
}
}
To deploy a cluster using Terraform, you must first modify the terraform.tfvars file. Open the terraform.tfvars file in the editor of your choice, and locate the cloud provider you will use to deploy a host cluster.
To simplify the process, we added a toggle variable in the Terraform template, that you can use to select the deployment
environment. Each cloud provider has a section in the template that contains all the variables you must populate.
Variables to populate are identified with REPLACE_ME.
In the example AWS section below, you would change deploy-aws = false to deploy-aws = true to deploy to AWS.
Additionally, you would replace all the variables with a value REPLACE_ME. You can also update the values for nodes in
the control plane pool or worker pool.
###########################
# AWS Deployment Settings
############################
deploy-aws = false # Set to true to deploy to AWS
aws-cloud-account-name = "REPLACE_ME"
aws-region = "REPLACE_ME"
aws-key-pair-name = "REPLACE_ME"
aws_control_plane_nodes = {
count = "1"
control_plane = true
instance_type = "m4.2xlarge"
disk_size_gb = "60"
availability_zones = ["REPLACE_ME"] # If you want to deploy to multiple AZs, add them here
}
aws_worker_nodes = {
count = "1"
control_plane = false
instance_type = "m4.2xlarge"
disk_size_gb = "60"
availability_zones = ["REPLACE_ME"] # If you want to deploy to multiple AZs, add them here
}
When you are done making the required changes, issue the following command to initialize Terraform.
terraform init
Next, issue the plan command to preview the changes.
terraform plan
Output:
Plan: 2 to add, 0 to change, 0 to destroy.
If you change the desired cloud provider's toggle variable to true, you will receive an output message that two new
resources will be created. The two resources are your cluster profile and the host cluster.
To deploy all the resources, use the apply command.
terraform apply -auto-approve
To check out the cluster profile creation in Palette, log in to Palette, and from
the left Main Menu click on Profiles. Locate the cluster profile with the name pattern
tf-[cloud provier]-profile. Click on the cluster profile to review its details, such as layers, packs, and versions.
You can also check the cluster creation process by navigating to the left Main Menu and selecting Clusters.
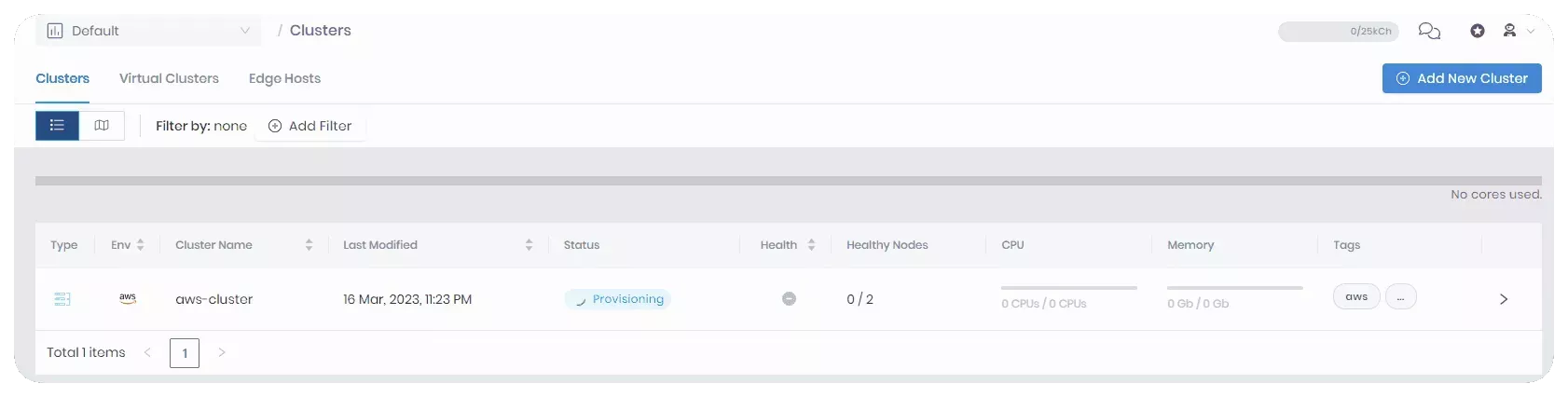
Select your cluster to review its details page, which contains the status, cluster profile, event logs, and more.
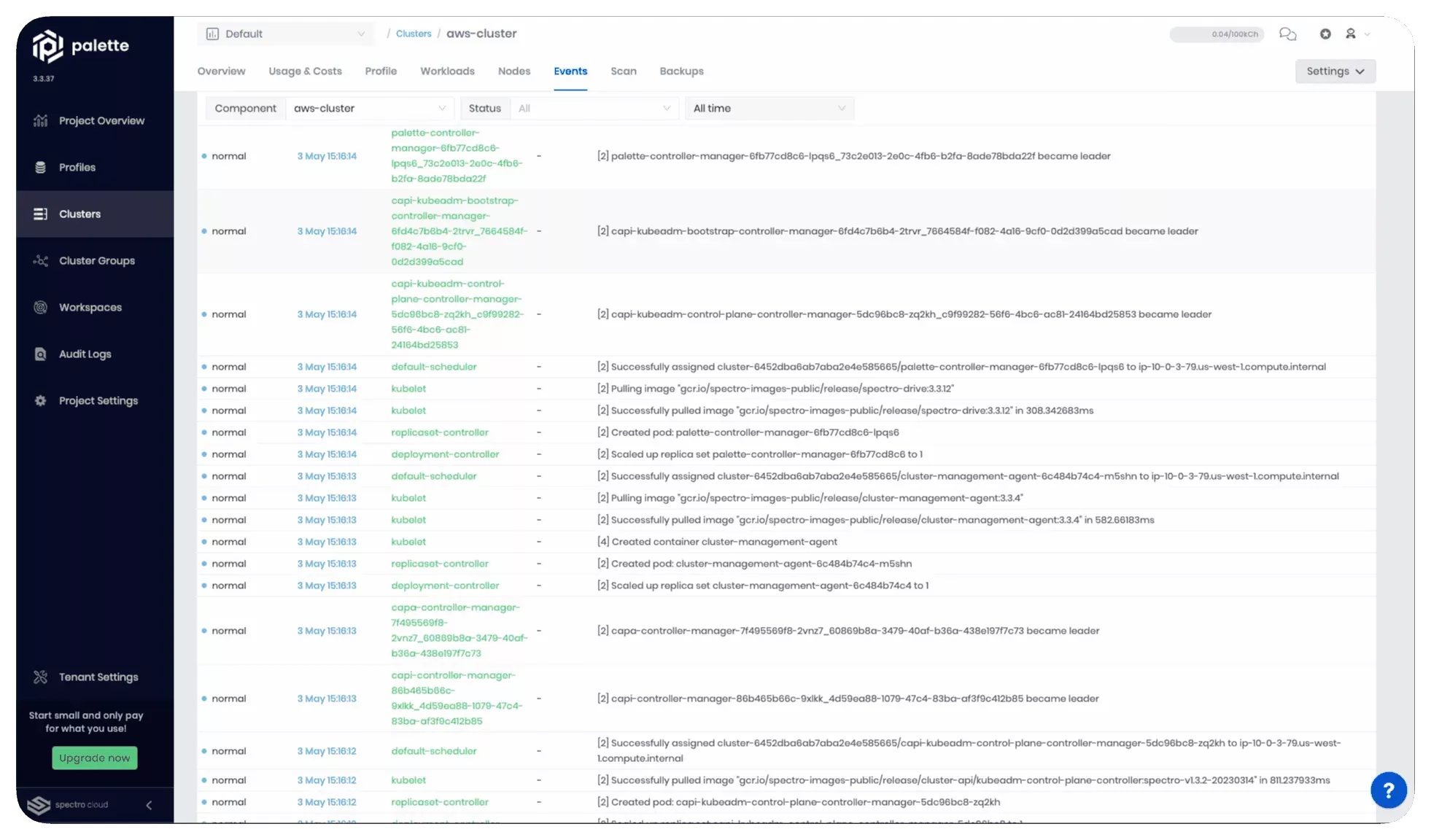
The cluster deployment may take several minutes depending on the cloud provider, node count, node sizes used, and the cluster profile. You can learn more about the deployment progress by reviewing the event log. Click on the Events tab to check the event log.
Verify the Application
When the cluster deploys, you can access the Hello Universe application. From the cluster's Overview page, click on the URL for port :8080 next to the hello-universe-service in the Services row. This URL will take you to the application landing page.
It can take up to three minutes for DNS to properly resolve the public load balancer URL. We recommend waiting a few moments before clicking on the service URL to prevent the browser from caching an unresolved DNS request.

Welcome to Hello Universe, a demo application to help you learn more about Palette and its features. Feel free to click on the logo to increase the counter and for a fun image change.
You have deployed your first application to a cluster managed by Palette through Terraform. Your first application is a single container application with no upstream dependencies.
Cleanup
Use the following steps to clean up the resources you created for the tutorial. Use the destroy command to remove all
the resources you created through Terraform.
terraform destroy --auto-approve
Output:
Destroy complete! Resources: 2 destroyed.
If a cluster remains in the delete phase for over 15 minutes, it becomes eligible for force delete. To trigger a force delete, navigate to the cluster’s details page and click on Settings. Click on Force Delete Cluster to delete the cluster. Palette automatically removes clusters stuck in the cluster deletion phase for over 24 hours.
If you are using the tutorial container and want to exit the container, type exit in your terminal session and press
the Enter key. Next, issue the following command to stop the container.
- Docker
- Podman
docker stop tutorialContainer && \
docker rmi --force ghcr.io/spectrocloud/tutorials:1.1.3
podman stop tutorialContainer && \
podman rmi --force ghcr.io/spectrocloud/tutorials:1.1.3
Wrap-Up
In this tutorial, you created a cluster profile, which is a template that contains the core layers required to deploy a host cluster. You then deployed a host cluster onto your preferred cloud service provider using Terraform.
We encourage you to check out the Deploy an Application using Palette Dev Engine tutorial to learn more about Palette. Palette Dev Engine can help you deploy applications more quickly through the usage of virtual clusters. Feel free to check out the reference links below to learn more about Palette.